
번역본 출처 : http://www.gpgstudy.com/gpgiki/InterviewWithJasonMitchell
원본 출처 :
href="http://www.4gamer.net/specials/gdc28/ati_1.html">http://www.4gamer.net/specials/gdc28/ati_1.html
번역기 : (Not)EzTransXP
GPU 관련의 인터뷰라고 하면, 상대가 하드웨어 사이드의 엔지니어인 것이 많았지만, 이번은 취향을 바꾸어,소프트웨어 사이드의 엔지니어의
인터뷰를 전달하자.
상대는,"ATI 3D Application Research Group"의Jason Mitchell씨.
Jason Mitchell씨라고 하면, 리얼타임 3 D그래픽스계에서는 상당한 유명인으로, 현재는 마이크로소프트에 근무해, 또프로그래머블
셰이더의 사양 책정에도 관여하고 있다중요 인물이다. 씨는 「SIGGRAPH」로 수많은 논문을 발표하고 있어 ATI RADEON 시리즈용의 데모
제작에도 관련되고 있는 만큼. 아시는 바 Futuremark의 3 D벤치마크 소프트 「3 DMark03」에 수록되고 있는 목제"상"상의
테스트는, 그의 셰이더 코드를 참고로 하고 있다(이 상에는, PixelShader2. 0에 의한 수속형 texture의 생성 셰이더 붙이기
처리가 베풀어지고 있다).
3 D그래픽스 관련의 컨벤션에서는 언제나 끌어당기기의 씨이지만, 이번 GDC에서는 인터뷰에 성공. 조속히, 그 모양을 전달하자.
 border=0>"ATI 3D Application Research Group"의 Jason Mitchell씨
border=0>"ATI 3D Application Research Group"의 Jason Mitchell씨
NVIDIA는,
href="GeForce?action=edit">?GeForce FX로 픽셀 셰이더 1.4를 서포트하지
않는다!?
니시카와 젠지(이하, 선) :
3 DMark03에 대해서 NVIDIA가 비판 성명을 낸 것은 아시는
바군요. 나도 그 논쟁에 관해서 취재를 하고 있는 한 사람입니다. 그리고 취재중, 이쪽의 질문에 대해서 NVIDIA로부터 「우리는 확실히 픽셀
셰이더 1.4[1]를
서포트하지 않는다」라고 하는 대답을 얻었습니다만, 확실히 픽셀 셰이더 2.0은 1.4의 슈퍼 세트군요?
Jason Mitchell씨(이하, JM) :
그것은 기묘한 이야기군요. 확실히 당신이
말하도록(듯이), 픽셀 셰이더 2.0은 1.4의 슈퍼 세트입니다.
선 :
개발자가 긴 셰이더를 쓰고 싶지 않으면, 1.4나 1.3을 선택할 수 있는 것이군요?
JM :
그 대로입니다. 마이크로소프트도 그러한 이용 방법을 전제로, 버젼 번호의 할당을 실시하고
있다고 생각합니다. 그러니까 개발자는, 자신이 개발하고 싶은 셰이더 프로그램에 적절한 셰이더 버젼을 결정할 수 있을 것입니다.
선 :
과연. 그러나, 이 건 붙어 취재를 계속할 필요가 있을 듯 하네요.
픽셀 셰이더로 정점 처리를 실시해?
선 :
GDC의 첫날의 세션으로, 마이크로소프트는 프로그래머블 셰이더 3.0의 사양을 분명히
했습니다(forGamer내의 기사는「
href="http://www.4gamer.net/news/history/2003.03/20030306192246detail.html">이쪽」).
사양에는, 마침내 정점 셰이더가 texture에 액세스 가능하게 되면(자) 있었습니다. 이것은 즉, 프로그래머블 셰이더 3.0세대의 GPU는,
텟세레이타[2]가
필요하게 되는 것을 의미하고 있습니까?
JM :
그것은 없다고 생각합니다. 정점 셰이더 3.0으로 텟세레이타는 분리되어 있을 것입니다.
정점 셰이더 3.0 사양은 「테크스체메모리에의 액세스의 구조를 제공한다」라고 하는 것입니다.
선 :
다만 테크스체메모리에 액세스 가능한 한이다, 라고?
JM :
물론 GPU에 텟세레이타가 있으면,"텟세레이션"이나"디스프레이스먼트맙핑"
class=footnote>[3]을 실수 없이 해낼 수
있겠지요.
선 :
그럼, 「정점 셰이더가 테크스체메모리에 액세스 할 수 있다」라고 하는 feature는, 어떤
활용 방법이 생각됩니까?
JM :
게임 개발자로부터는 「현행 사양에서는 정수 영역이 작다」라고, 자주(잘) 지적됩니다.
게임 개발자는, 본스키닝
name=footrev-4-0>[4]을 실시할 때, 많은 뼈를 사용하고 싶어합니다. 각각의 뼈는 행렬로 표현해 정수 영역에
격납합니다만, 뼈가 너무나 증가하면(자), 이 정수 영역으로부터 흘러넘쳐 버립니다.
선 :
그러한 문제에 조우했을 때, 현재의 GPU 베이스에서는 어떻게 회피합니까?
JM :
그 경우는, 캐릭터를 분해해 그룹 마다 스키닝 처리를 실시합니다. 다만 이 방법은 매우
복잡하고, 관리가 귀찮습니다.
테크스체메모리에 정점 셰이더를 액세스 할 수 있게 되면(자), 그러한 뼈 정보는 테크스체메모리에 넣어 둘 수 있습니다. 그러면 뼈를 그룹
으로 분해하는 일 없이, 통째로 처리할 수 있는 것입니다.
선 :
디스프레이스먼트맙핑에 대해서는 어떨까요? 이번 GDC에서는, ATI의 기술자가
디스프레이스먼트맙핑의 훌륭함을 포교한다(? ) 세션을 열고 있었습니다만, 현행의 GPU가 이 기술을 서포트하고 있지 않는 이상, 간편하게는 손을
댈 수 없다고 생각합니다만…….
JM :
그렇네요. 이 근처는 GPU 뿐만이 아니라 CPU의 경우도 같은 것을 말할 수 있습니다.
우리 하드웨어 벤더는, 사용하기 쉽게 뛰어난 것을 신기능으로서 소개해, 그것을 사용할 수 있도록(듯이) 포교할 필요가 있는 것으로……(웃음)
 border=0>
border=0>
src="http://www.4gamer.net/specials/gdc28/images/003s.jpg" border=0> 같은 기본
모델에 대해서 정점 texture를 붙여 형상을 지오메트리레벨로 변형시킨다」라고 하는 디스프레이스먼트맙핑. 확실히 획기적이지만……
텟세레이타는 DirectX 9세대 GPU에 필요한가?
선 :
적응형 텟세레이타(Adaptive Tessellator)라고 하는 것은, RADEON
9700(이하, R9700) 계 특유의 기능입니까?
JM :
네? 아니, R9700계에 적응형 텟세레이타는 없어요 (웃음)
TRUFROM2. 0은 연속형 텟세레이타(Continuous Tessellator)입니다. 텟세레이타에는, 이산형
텟세레이타(Discrete Tessellator), 연속형 텟세레이타, 적응형 텟세레이타의 3개의 정의가 있는 것을 아시는 바입니까?
선 :
혼동 하고 있었던 (웃음)
JM :
용어의 정의는 어려우니까. 이산형은, 이산 한 만큼 비율 메소드로 텟세레이션을 실시하는
텟세레이타입니다. RADEON 8500(이하, R8500)의 텟세레이타의 「N-PATCH」는 이것에 상당합니다. 또 연속형은 R9700계로
서포트되어서 , 분할하는 정밀도를 분수나 소수로 주어집니다.
선 :
텟세레이타는 디스프레이스먼트맙핑 뿐만이 아니라, 장래적으로는 동적 LOD
class=footnote>[5]까지를 서포트할 수
있다고 생각하고 있습니다만, 어떻게 생각됩니까.
JM :
나도 그 대로라고 생각하고 있습니다. 그 외 , 고차 서페스의 서포트도 대상이 되겠지요.
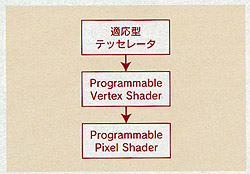 border=0>DirectX 9세대 GPU의 처리계의 블록 다이어그램. 텟세레이타가 없어도 DirectX 9세대 GPU를 자칭할
border=0>DirectX 9세대 GPU의 처리계의 블록 다이어그램. 텟세레이타가 없어도 DirectX 9세대 GPU를 자칭할
수가 있다
선 :
우리를 모르는 것은, 텟세레이타의 자리 매김입니다. DirectX 9세대의 GPU에서는,
그림과 같은 구성이라고 설명되었습니다. 이것은"텟세레이타가 필요하다"라고 이해했습니다만, NVIDIA
class=wikiunknown>?GeForce FX 등은
텟세레이타를 가지고 있지 않아요.
JM :
실제로는, DirectX feature의 대부분이 옵션 설정입니다. DirectX로
소개되는 기능의 상당수는 GPU로 처리되어야 할 일입니다만, 예를 들면, 고차 서페스의 서포트 등은 옵션이 되어 있습니다. 게임 개발자는, 동작
대상이 되는 GPU가 어느 기능을 서포트하고 있는지를 음미할 필요가 있습니다.
선 :
텟세레이타는 필요없습니까?
JM :
장래적으로는, 텟세레이션이 통합되어 정점 셰이더의 전후로 텟세레이션을 실시할 수 있는 것
같은 구조가 제공될지도 모릅니다.
정점 셰이더와 픽셀 셰이더가 texture를 공유할 수 있으면 「먼저 픽셀 셰이더로 정점 처리를 실시해, 이것을 텟세레이타에 되돌린다」같은
일도 할 수 있겠지요.
현행의 R9700/RADEON 9800(이하, R9800)은, 픽셀 셰이더 실수 연산 정밀도가 24 비트이므로, 정점 셰이더의 연산
정밀도와 정밀도적으로 어울리고 있지 않습니다. 캐릭터의 로컬 좌표계의 처리에는 문제 없다고 생각합니다만, 지형등의 글로벌 좌표계 전체에 퍼지는
것의 처리에는 문제가 나올지도 모르네요.
선 :
「픽셀 셰이더가 정점 처리를 한다」 것은 이미지 하기 어렵습니다만, 어떻게 된 일입니까?
JM :
통상, 정점 셰이더는 연산 결과를 메모리에 써냅니다. 그 출력을 기본으로, 트라이앵글
셋업부(rasterize 엔진)는, 화면상의 어느 픽셀이 될까를 결정합니다. 즉"정점이 픽셀을 낳는"이라고 생각해도 좋을 것입니다.
픽셀 셰이더는, 메모리로부터 데이터를 읽어들여 연산해, 출력을 각 색채널에 써냅니다. 정점 셰이더와 픽셀 셰이더의 연산 정밀도가 32 비트
정밀도로 같게 되면(자) 「픽셀 셰이더가 정점 버퍼로부터 데이타를 뽑기 시작해 처리한다」라고 하는 일도 가능하게 되는 것입니다.
선 :
즉 「픽셀 셰이더가 정점 버퍼로부터 정점 데이타를 뽑기 시작해 연산해, 다시 정점 버퍼에 써
되돌린다」라고 하는 것입니까.
JM :
그렇습니다. 즉 픽셀 셰이더는 「연산 결과를 임의의 버퍼에 써내는 정점 셰이더」로서 활용할
수 있습니다.
저다각형으로 표현된 모델의 정점 버퍼를 취득해, 픽셀 셰이더로 본스키닝 해, 이것을 다른 버퍼에 출력합니다. 이 버퍼를 정점 셰이더로
취득해, 텟세레이션 하거나 다시 정점 연산하거나……라고 했던 것(적)이 가능하게 됩니다.
선 :
그러한"기술"은, 구체적으로 어떤 일로 응용할 수 있는 것입니까.
 border=0>이 데모의 캐릭터 다각형은, 시점으로부터의 거리에 응해 변화하는 LOD를 채용하고 있지만, 정점 증감은, 정점 셰이더
border=0>이 데모의 캐릭터 다각형은, 시점으로부터의 거리에 응해 변화하는 LOD를 채용하고 있지만, 정점 증감은, 정점 셰이더
어시스트의 CPU 텟세레이션으로 실현되고 있다
JM :
예를 들면, 옷감의 움직임의 재현(이른바 「Cloth 시뮬레이션」)이군요. 그리고는 수면의
움직임의 시뮬레이션도, 이것으로 완성된다고 생각합니다. 이러한 예는, RADEON의 연산 정밀도의 픽셀 셰이더로, 문제 없게 실현될 수 있다고
생각합니다.
선 :
그렇게 말한 데모를 만드시지 않습니까? (웃음)
JM :
만들어요. 언젠가는 말할 수 없습니다만 (웃음). 현재 이러한 테크놀러지의 이용은
「SIGGRAPH」의 논문에도 좋게 개인가 나와 있네요. 기체의 시뮬레이션이라든지, 유체학의 시뮬레이션이라든지.
선 :
"정점 셰이더 처리의 후에 텟세레이션"이라고 하는 것은, 구체적으로 어떤 응용이 생각됩니까?
JM :
예를 들면, 정점수의 적은 저다각형 메쉬
href="#footnote-6" name=footrev-6-0>[6]로 캐릭터를 구성해, 이것을 기본으로 본스키닝 처리해
동작. 그 후 텟세레이타로 디스프레이스먼트맙핑 하는……은 일이 생각되네요.
픽셀 셰이더의 연산 정밀도 문제 RADEON 9700계가 빨라서 href="GeForce?action=edit">?GeForce FX가 늦은 이유
선 :
GDC의 세션으로, NVIDIA의 기술자가 「실행 속도가 빠른 16 비트 정밀도의 실수
카라서페스를 활용합시다」라고 말했습니다. R9700계는 내부 24 비트 정밀도로 연산하는군요. 이 아키텍쳐는 어떤 경위로 태어났겠지요?
JM :
ATI도, 1년 전부터 16 비트 정밀도와 32 비트 정밀도의 실수 칼라 표현에 대해,
논의를 하고 있었습니다.
24 비트 정밀도 포맷의 책정도 생각하고 있었습니다만, 가까운 시일내에 모든 GPU가 32 비트 정밀도 포맷을 당연하게 해낼 수 있게 될
것이므로, 이것은 그만두기로 했습니다.
선 :
한 번 사양으로서 만들어 버리면(자), 당분간 남게 되니까요.
JM :
그렇습니다. 32 비트 정밀도의 연산기를 실장하려면 , 트랜지스터 카운트 제한의
관점으로부터 하면(자) 실장할 수 있을 것 같지 않으면 알게 되었고. 그러나, 16 비트 정밀도에서는 과연 정밀도가 부족하다. 거기서 트레이드
오프가 되는 24 비트 정밀도 연산기를 실장했습니다.
선 :
16 비트 정밀도에서는 어떤 풀어에 문제가 나오는 것입니까.
JM :
우선 예로서 들고 있는 것은, 벡터의 재정규화(벡터의 방향은 바꾸지 않고 절대치를 1으로
한다)군요. 이 연산은 16 비트 정밀도에서는 문제가 나옵니다.
선 :
비주얼적으로는 어떠한 문제가 나옵니까.
JM :
정규화한 벡터는"큐브 환경 맵"의 참조에 사용합니다. 환경 맵 참조의 정밀도가 내리면,
비치는 화상의 품질이 내립니다.
 border=0>3 DMark03의 PixelShader2. 0Test. 32 비트 정밀도 실수 연산을 다용하는 픽셀 셰이더
border=0>3 DMark03의 PixelShader2. 0Test. 32 비트 정밀도 실수 연산을 다용하는 픽셀 셰이더
프로그램이 실행되기 (위해)때문에,
href="GeForce?action=edit">?GeForce FX계는 R9700계의 반정도의 퍼포먼스 밖에
나오지 않는다
선 :
과연. 퍼포먼스와 정밀도의 양쪽 모두가 뛰어난 24 비트 정밀도를 ATI는 선택했다……라고
하는 것습니다.
JM :
그렇습니다. 게임은 물론, RENDERMAN 컨텐츠의 렌더링도, 24 비트 정밀도로
충분하다고 생각하고 있습니다. 확실히 이 수법에서는, 32 비트 정밀도의 실수 데이터로부터 24 비트 정밀도에의 변환 처리라고 하는 오버헤드가
있습니다만.
선 :
R9700계를 사용하는 한은, 16 비트 정밀도, 32 비트 정밀도에 대해 신경쓸 필요는
없다고 하는 것이군요.
JM :
NVIDIA가 32 비트 연산기를 채용한 것은 매우 자연스러운 일입니다만, 퍼포먼스가
오르지 않는 것은 불행한 일이라고 생각합니다.
선 :
href="GeForce?action=edit">?GeForce FX의 퍼포먼스가 오르지 않는 이유는 압니까?
(웃음)
JM :
나는 그들의 GPU의 아키텍쳐에 자세하지 않으니까 (웃음) 단언할 수 없습니다만, 32
비트 실수 연산이 2 파이프라인으로 공유되고 있어, 실행이 분단 되고 있는 것 같은 생각이 듭니다. 그래서 특수 케이스, 예를 들면
데프스밧파(Z버퍼)에의 출력시 밖에, 8 픽셀 출력을 할 수 없는 것이 아닐까.
선 :
3 DMark03의 픽셀 셰이더 2.0 테스트의 결과 등은, 확실히
class=wikiunknown>?GeForce FX에는
괴롭네요.
JM :
저것은 32 비트 정밀도 실수 픽셀 연산을 다용하고 있으니까요.
class=wikiunknown>?GeForce FX에는
괴로울 것입니다.
선 :
R9700/R9800는, 32 비트 실수 픽셀 연산을 어떻게 처리하고 있습니까?
JM :
통상은 4 픽셀 동시에 처리합니다. R9700/R9800는 4 픽셀 단위로 처리하는 기능을
2개탑재 하고 있어, 우리는 이것을 콰드라고 부르고 있습니다. 이 콰드는, 각각이 독립해 동작합니다.
선 :
RADEON 9500/9600(이하, R9500/R9600)는, 콰드가 하나의 버젼이라고
하는 것습니다.
JM :
예를 들면, 다른 한쪽의 콰드중이 있는 파이프로 texture 액세스를 실시했기 때문에
stall 했다고 해도, 이 처리는 한편의 콰드에는 무관계해서 실행은 계속됩니다. 이렇게 해, 각각의 콰드는 multi-thread와 같은
형태로 실행해 나가는 것입니다.
그러나, 2개의 콰드는 임시 레지스터등을 공유하고 있습니다. 그 때문에 공유 영역이 가득하게 되면(자), 다른 한쪽의 콰드의 실행이 늦는
경우가 있습니다.
선 :
쓸데없게 레지스터를 사용하고 있으면(자), throughput에 영향이 나올 가능성이 있는
것이군요.
JM :
그 때문에, 셰이더 컴파일러의 오프티마이자는, 레지스터 사용이 최저한이 되도록(듯이)
최적화하고 있습니다.
부동 소수점 실수 픽셀 포맷의 가까운 미래
선 :
DirectX 9로 새롭게 규정된 부동 소수점 실수 픽셀에는, 겉(표)와 같은 제한이
있습니다. 「실수 픽셀에서는 필터링이나 아르파브렌딘그를 할 수 없다」라고 하는 것은 매우 큰 제약이라고 생각됩니다만.
 border=0>DirectX 9세대 GPU로 서포트된 각종 칼라 포맷의 제약표
border=0>DirectX 9세대 GPU로 서포트된 각종 칼라 포맷의 제약표
JM :
현행의 GPU가 반드시 이러한은 있는……이라고 규정하는 것은 아닙니다. 「
class=wikiunknown>
href="CheckDeviceFormat?action=edit">?CheckDeviceFormat()」를
실행해, GPU가 어느 feature를 서포트하고 있을지 어떨지를 판단해야 합니다.
선 :
DirectX 9세대 GPU에서도, 이러한 제약이 없는 것이 나올 가능성이 있기 때문이군요.
JM :
그렇습니다. 이 표에 있는 것 같은 제약은, 현행의 프로세서의 제조 프로세스 룰로
현실적으로 실장할 수 있는 트랜지스터 카운트 제약이라고 할 수 있습니다. 그 때문에, 이러한 제한이 주어지고 있을 뿐입니다(프로세스 룰은,
R9700/R9800가 0.15μm,
href="GeForce?action=edit">?GeForce FX5800계가 0.13μm). 그러니까 차세대
GPU에서는 철거해진다고 생각합니다.
R9700/R9800는 각 파이프에 카라브렌다가 있습니다만, 실수 대응화해 아픈들 , 트랜지스터 카운트는 좀 더 증가해 코스트가 비싸지고
있던 것이지요.
선 :
그러나 게임 개발자로부터는, 이러한 제한이 철거해지지 않으면 게임 용도에 사용하는 것은
괴로운, 이라고 하는 소리도 있는 것 같습니다.
JM :
확실히 그렇게 말한 지적은 우리도 인지하고 있습니다. 우리가 특히 중요시하고 있는 것은
「32 비트 실수 포맷의 브렌딘그를 할 수 없다」라고 하는 점입니다. 이것들은 하이 다이나믹 레인지(HDR) 렌더링
class=footnote>[7] 때, 매우 유용합니다.
우리의 「Rendering With Natural Light」라고 하는, R9700의 HDR 데모를 기억하고 있습니까?
선 :
그"빛의 모야"가 걸리는 구체의 데모군요. 저것은 개화 필터에 의해 생성된"빛의
안개"프레임과 오리지날의 장면을 합성하고 있는군요.
JM :
그 데모에서는 각 색채널 16 비트의 ABGR16 포맷을 채용하고 있습니다만, 합성에
아르파브렌딘그를 사용하고 있습니다. ……그렇다고 할까 사용할 수 없었기 때문에, 픽셀 셰이더로 색연산해 합성하고 있습니다.
 border=0> ATI의 데모 「Rendering With Natural Light」. 실행 파일이나 무비는
class=namedurl href="http://www.ati.com/developer/demos/r9700.html">「이쪽」으로부터
border=0> ATI의 데모 「Rendering With Natural Light」. 실행 파일이나 무비는
class=namedurl href="http://www.ati.com/developer/demos/r9700.html">「이쪽」으로부터
입수 가능
선 :
실수 픽셀 포맷의 MIP-MAP에 관해서는 어떻습니까?
JM :
R9700에서는 벌써 서포트하고 있습니다. 실수 픽셀에서도 MIP-MAP, 큐브 맵, 볼륨
맵을 서포트하고 있습니다.
선 :
그러나 필터링은 서포트되지 않기 때문에, MIP-MAP를 이용했을 때의 정밀도는 떨어져
버리는 것이군요.
JM :
그 대로입니다. 이것도 머지않아 해결되어야 할 제약이군요. 장래적으로는, 바이리니아나
트라이 리니어, 아니소트로픽크라고 하는 필터가 서포트되어, 다른 서페스와 같게 이용할 수 있게 된다고 생각합니다.
선 :
새로운 세대의 GPU에서는 할 수 있는 것이 증가합니다만, 할 수 있는 것의 안에 다른
제약이 주어지고 있어, 이것이 차세대에서는 철거해진다. 그렇지만 거기에는, 또 새로운 기능이……라고 하는 것이 반복해져 가는 것이군요 (웃음).
오늘은 감사합니다.
[1] ATI
RADEON 8500은, DirectX 8.0의 픽셀 셰이더 사양의 확장 명령 세트를 갖추고 있었다. 이것은 후에, 픽셀 셰이더 1.4로서
DirectX 8.1에 인플리맨트 되는 것에
[2] 다각형을
분할하는 유니트를 텟세레이타라고 해, 다각형 분할 처리를 텟세레이션이라고 한다
[3] 다각형에
요철을 붙이는 처리. 범프 맵핑은"요철이 있도록(듯이)"음영 처리를 실시할 뿐(만큼)의 가짜이지만, 디스프레이스먼트맙핑은 입체 그 자체를 생성해
정점 생성하므로, 다각형 분할의 처리계를 빠뜨릴 수 없다
[4] 3 D캐릭터의
동작시, 신축 하는 외피가 파탄하지 않게 정점을 브렌드(정점 브렌딘그) 해 자연스럽게 보완(스키닝)하는 구조
[5] Level
of Detail의 약어. 시점으로부터의 거리에 응해 3 D모델의 다각형수를 증감해, 묘화 부하를 경감하는 기술. 3 D게임 엔진에는 필요
불가결한 기술로, 현재는 CPU가 처리하고 있다
[6] 3 D캐릭터
모델. 3 D캐릭터의 다각형편이 꼭"뜨게질 코"와 같이 보이는 것으로부터, 이와 같이 불리게 되었다
[7] 종래 ARGB
각 8 비트, 합계 32 비트 칼라(1677만색차원)로 렌더링 하고 있던 것을, 실수 칼라 표현을 채용해 폭의 넓은 표현색으로 렌더링을 실시하는
것. 색 가지수를 늘리는 목적은 아니고, 연산 정밀도를 올리기 위해서(때문에) 도입되었다
'정보기술 > 일반' 카테고리의 다른 글
| [정보] Canon IXUS V3 아답터 정보 (0) | 2003.07.10 |
|---|---|
| Game Programming Gems 스터디 (0) | 2003.07.09 |
| [정보] Asus FX5600 V9560 VS - 엔씨소프트, FX5600 초특가 판매 시작 !!! (0) | 2003.07.09 |
| [정보] 무선인터넷 네스팟 공동청약 7/31 까지 (0) | 2003.07.08 |
| [보안] P2P 사용 포트 (0) | 2003.07.08 |